![]() Figure 2 of
Wistow, Mol Vis 2002;
8:164-170.
Figure 2 of
Wistow, Mol Vis 2002;
8:164-170.
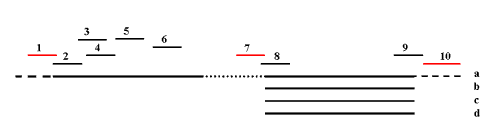
Figure 2. Schematic Assembly of a GRIST cluster
Ten different ESTs (1-10) have been grouped together into one cluster. The numbered lines represent EST sequences. Lines a-d represent multiple entries in GenBank for cDNAs derived from the same gene. Sequence fragments shown in black all match GenBank sequences. Numbers 8 and 9 preferentially match the short sequences, b-d. Numbers 2-6 only match the longer sequence a. The black sequences are grouped together in Step 1 of GRIST through a relational chain since they have some high quality (HQ) GenBank matches in common. The EST sequences in red [1,7,10] are derived respectively from 5' UTR (dashed line in part "a"), an alternative splice product (dotted line in part "a"), and 3' UTR (dashed line in part "a") sequences that are not represented in any of the GenBank targets, but whose positions are shown relative to the long sequence "a". They join the cluster in Step 2 of GRIST because they overlap with other ESTs in the cluster in "self-match". Other steps in GRIST examine names, UniGene relationships and ORFs for this cluster.