![]() Figure 1 of
Coleman, Mol Vis 2004;
10:720-727.
Figure 1 of
Coleman, Mol Vis 2004;
10:720-727.
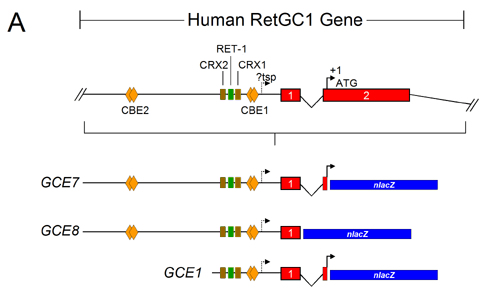
Figure 1. Schematics and sequence of the human retGC1 promoter-nlacZ transgenes used in the lentiviral vectors
A: Schematics showing the exon-intron structure and location of putative cis-elements in the human retGC1 5' flanking sequence and the lentiviral vector transgene constructs that were used to generate virus. Exons are shown as red rectangles surrounding intron 1 (bent line). The nlacZ open reading frame is shown as a blue rectangle. ATG represents the translation start site (arrow denotes the position of A = +1); "?tsp" marks a putative transcription start point (arrow denotes the position of first "A" that aligns with the "A" in the bovine GC1 tsp; see text and B, below); brown rectangles illustrate putative inverted cone-rod homeobox (CRX) protein binding sites; orange diamonds refer to putative head to tail CRX binding elements (CBEs); the green rectangle represents a putative Ret-1 binding site. The color coding and nucleotide positions are uniform across panels and figures. B: Sequence showing the entire GCE7 promoter fragment (which also contains the GCE1 and GCE8 fragment sequences) and the point of fusion with the nlacZ gene in the lentiviral vector constructs. The turquoise A at position -425 indicates the putative tsp identified by aligning the human and bovine retGC1 promoter sequences (GenBank accession number U77096). The Inr-like sequence that is also found in the bovine retGC1 5' flanking region is shown in lowercase [28]. The putative inverted CRX binding elements and Ret-1 binding element are highlighted in brown and green, respectively. The AT rich repeats are shown in purple. Exon 1 and exon 2 sequences flanking intron 1 are shown in red. The red line (|) indicates the translation start point of human retGC1 (ATG, where the A is defined as position +1); the sequence at the start of the nlacZ open reading frame is in blue. Vector and restriction enzyme cloning sequences are in dark purple.
B:
NotI
--------
GCGGCCGCTC TGCTCCTCAT CCAACATTTC CCCCAGCTTT AGAATCCACT
GATGATTCTT ACCTGATCCA ATCTTTGCCA CCAAGTCTGA AAATGATTCA -1655
TTTAAAAGTT TTTAAGTTTT ATTTTTCACA TATAGATCTT TGACCTGGAA
TAGATTTTGT GTATGGTGTG AGATAGGGAT TGAATTCTAT TTTCCCCCCA -1555
CBE2
------------
GATGGCTAAT CAGCTCCATT TGTTGAAGTT TATTCTTTCC AAGTTGGTAA
GAAATGTCCA CGTCTTCACA CATTTGCTGT GTTTGTTTCA GTACTGTATA -1455
TTCTATTTCA TTGGTCCATT TGTTTATCCT TGTGCCAAAA CTATGAAGTC
TTTATTGCCA TAGCTTTATA ATATATATTT ATATAAATAT ATAATTGCTG -1355
TCACTACATA ATGTGGATTT ATATAAATAT ATAATATATA ATTGCTATAG
CTTTATAGTA TATATTTATA TAATTGCTGT TTTATATATC ATATAATTAT -1255
ATAAATATAT AATTGCTATG TTTTATATAT TATATATTTA TGTAGATATA
TAATTGCTAT GTTTTATATA TTATATATTT ACATAAATAC ATAATTGCTA -1155
TTGCTTTATA ATAAATTTGT ATATCTTATA GGGCATCTTC CATTATACTC
TTCTCTAAAA TTGTTAGCTA TTCTTGCCAT CCGGGCGATT ATATTCATTT -1055
TCACAACAAC CCTCAGATTA AGCAATTGCC CAAGGTCCAA AAATCAGCAA
GAGGGACTTG GAACCCAGGT CTGTCGGAGG CCAAAGCTCT TTTCATTACT -955
TCTTGAGGGT GGTTTTCTAG GCATGGAGAA GCAGAGGTCA GGGAATCAAG
TGTGGCGAGA GAGAGAAGAG AAGTGAAAGA AGAARGGCAG GTGTCAGCTT -855
GGTGTGGGTT TGGTCTCTGG GATATAGACT TTGCCAGCCA AAGGATGGAG
CTTGAACTTA GCCGGCAGAA CTGGAAACAG AAGATTGTAA GGAAAGGGAC -755
TGGGATCAGT GTTTCTTCTC CAGGACGGAT TACCCACAGC TGTCCACGGG
CAGGCACTTG TTACTTTCTG GCTGAGCAGG GCAGTGTGGC CGACGGCTGA -655
AAGGGGAAGC TGCGGCTGCT TTTGCGCAGG GGTGGTGGTG ATGAGGGTGA
TGTGGGGGGC TGGAAGGCAT GGAGGGGAAA GGATCTGGCT GACTACCTGG -555
AAGCCAGGAC AGATCCCACC CCAGAAAGGC GCAGTAGGGG CTCTCATCCT
CBE1
------------
CCACTAGCCC GCCCCTCCCT ACCTAATTAA GGACCCTAAT CAGCTTTGGG -455
GAGATTAAGG GCTCTGGCCG GCTGTACccA cgccCCCGCC CTGGCCTGGG
CTGGCAAGGA AGACCTGTGG GCGGGCGTCA AAAGGGGGAC CGGCCCTGTG -355
ACCCCTCACC GGGGCCGTGG GCCCGAGCCC CGGACTTCCC TGTAAGTGTC
AGAGGCCCCT CCGCTGGGAT AGGGTCGGTC TGAGGGCGCA GGCGAGTCCC -255
TGCTGACCCC TGACGCCTCC GACGGGGGGA GGGGCAGGCC GGGTGGGAGC
GGGAAGCCGG GGCGGCAGAA GGGGGCTTCG GGGCGGTGTC CTTGGCCCCA -155
GTTAGTCTTC CCAGCCTCCG GAGGGGGCGG TAGCAGCAGA ATCATCCCAT
GGGTTACTCG GGCTTGGAGA AACTCGGGGT TACGGGGAGA ACCCTAGGGG -55
AGGCCGGGGT CTCAGTCGCT CAGCCTGCTC CGTCTGTGTT CGCAGAAGCC
+1 PmeI nlacZ
| ------- --------------------
GGCAATGACC GTTTAAACTT AAGCTTCCAC CATGCCTAAG AAGAAACGAA
|